第五章:异步Web服务¶
到目前为止,我们已经看到了许多使Tornado成为一个Web应用强有力框架的功能。它的简单性、易用性和便捷性使其有足够的理由成为许多Web项目的不错的选择。然而,Tornado受到最多关注的功能是其异步取得和提供内容的能力,它有着很好的理由:它使得处理非阻塞请求更容易,最终导致更高效的处理以及更好的可扩展性。在本章中,我们将看到Tornado异步请求的基础,以及一些推送技术,这种技术可以使你使用更少的资源来提供更多的请求以编写更简单的Web应用。
5.1 异步Web请求¶
大部分Web应用(包括我们之前的例子)都是阻塞性质的,也就是说当一个请求被处理时,这个进程就会被挂起直至请求完成。在大多数情况下,Tornado处理的Web请求完成得足够快使得这个问题并不需要被关注。然而,对于那些需要一些时间来完成的操作(像大数据库的请求或外部API),这意味着应用程序被有效的锁定直至处理结束,很明显这在可扩展性上出现了问题。
不过,Tornado给了我们更好的方法来处理这种情况。应用程序在等待第一个处理完成的过程中,让I/O循环打开以便服务于其他客户端,直到处理完成时启动一个请求并给予反馈,而不再是等待请求完成的过程中挂起进程。
为了实现Tornado的异步功能,我们构建一个向Twitter搜索API发送HTTP请求的简单Web应用。这个Web应用有一个参数q作为查询字符串,并确定多久会出现一条符合搜索条件的推文被发布在Twitter上("每秒推数")。确定这个数值的方法非常粗糙,但足以达到例子的目的。图5-1展示了这个应用的界面。
图5-1 异步HTTP示例:推率
我们将展示这个应用的三个不同版本:首先,是一个使用同步HTTP请求的版本,然后是一个使用带有回调函数的Tornado异步HTTP客户端版本。最后,我们将展示如何使用Tornado 2.1版本新增的gen模块来使异步HTTP请求更加清晰和易实现。为了理解这些例子,你不需要成为关于Twitter搜索API的专家,但一定的熟悉不会有害。你可以在https://dev.twitter.com/docs/api/1/get/search阅读关于搜索API的开发者文档。
5.1.1 从同步开始¶
代码清单5-1包含我们的推率计算器的同步版本的代码。记住我们在顶部导入了Tornado的httpclient模块:我们将使用这个模块的HTTPClient类来执行HTTP请求。之后,我们将使用这个模块的AsyncHTTPClient。
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
import tornado.httpclient
import urllib
import json
import datetime
import time
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
class IndexHandler(tornado.web.RequestHandler):
def get(self):
query = self.get_argument('q')
client = tornado.httpclient.HTTPClient()
response = client.fetch("http://search.twitter.com/search.json?" + \
urllib.urlencode({"q": query, "result_type": "recent", "rpp": 100}))
body = json.loads(response.body)
result_count = len(body['results'])
now = datetime.datetime.utcnow()
raw_oldest_tweet_at = body['results'][-1]['created_at']
oldest_tweet_at = datetime.datetime.strptime(raw_oldest_tweet_at,
"%a, %d %b %Y %H:%M:%S +0000")
seconds_diff = time.mktime(now.timetuple()) - \
time.mktime(oldest_tweet_at.timetuple())
tweets_per_second = float(result_count) / seconds_diff
self.write("""
<div style="text-align: center">
<div style="font-size: 72px">%s</div>
<div style="font-size: 144px">%.02f</div>
<div style="font-size: 24px">tweets per second</div>
</div>""" % (query, tweets_per_second))
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application(handlers=[(r"/", IndexHandler)])
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
这个程序的结构现在对你而言应该已经很熟悉了:我们有一个RequestHandler类和一个处理到应用根路径请求的IndexHandler。在IndexHandler的get方法中,我们从查询字符串中抓取参数q,然后用它执行一个到Twitter搜索API的请求。下面是最相关的一部分代码:
client = tornado.httpclient.HTTPClient()
response = client.fetch("http://search.twitter.com/search.json?" + \
urllib.urlencode({"q": query, "result_type": "recent", "rpp": 100}))
body = json.loads(response.body)
这里我们实例化了一个Tornado的HTTPClient类,然后调用结果对象的fetch方法。fetch方法的同步版本使用要获取的URL作为参数。这里,我们构建一个URL来抓取Twitter搜索API的相关搜索结果(rpp参数指定我们想获得搜索结果首页的100个推文,而result_type参数指定我们只想获得匹配搜索的最近推文)。fetch方法会返回一个HTTPResponse对象,其 body属性包含我们从远端URL获取的任何数据。Twitter将返回一个JSON格式的结果,所以我们可以使用Python的json模块来从结果中创建一个Python数据结构。
fetch方法返回的HTTPResponse对象允许你访问HTTP响应的任何部分,不只是body。可以在官方文档[1]阅读更多相关信息。
处理函数的其余部分关注的是计算每秒推文数。我们使用搜索结果中最旧推文与最新推文时间戳之差来确定搜索覆盖的时间,然后使用这个数值除以搜索取得的推文数来获得我们的最终结果。最后,我们编写了一个拥有这个结果的简单HTML页面给浏览器。
5.1.2 阻塞的困扰¶
到目前为止,我们已经编写了 一个请求Twitter API并向浏览器返回结果的简单Tornado应用。尽管应用程序本身响应相当快,但是向Twitter发送请求到获得返回的搜索数据之间有相当大的滞后。在同步(到目前为止,我们假定为单线程)应用,这意味着同时只能提供一个请求。所以,如果你的应用涉及一个2秒的API请求,你将每间隔一秒才能提供(最多!)一个请求。这并不是你所称的高可扩展性应用,即便扩展到多线程和/或多服务器 。
为了更具体的看出这个问题,我们对刚编写的例子进行基准测试。你可以使用任何基准测试工具来验证这个应用的性能,不过在这个例子中我们使用优秀的Siege utility工具进行测试。它可以这样使用:
$ siege http://localhost:8000/?q=pants -c10 -t10s
在这个例子中,Siege对我们的应用在10秒内执行大约10个并发请求,输出结果如图5-2所示。我们可以很容易看出,这里的问题是无论每个请求自身返回多么快,API往返都会以至于产生足够大的滞后,因为进程直到请求完成并且数据被处理前都一直处于强制挂起状态。当一两个请求时这还不是一个问题,但达到100个(甚至10个)用户时,这意味着整体变慢。
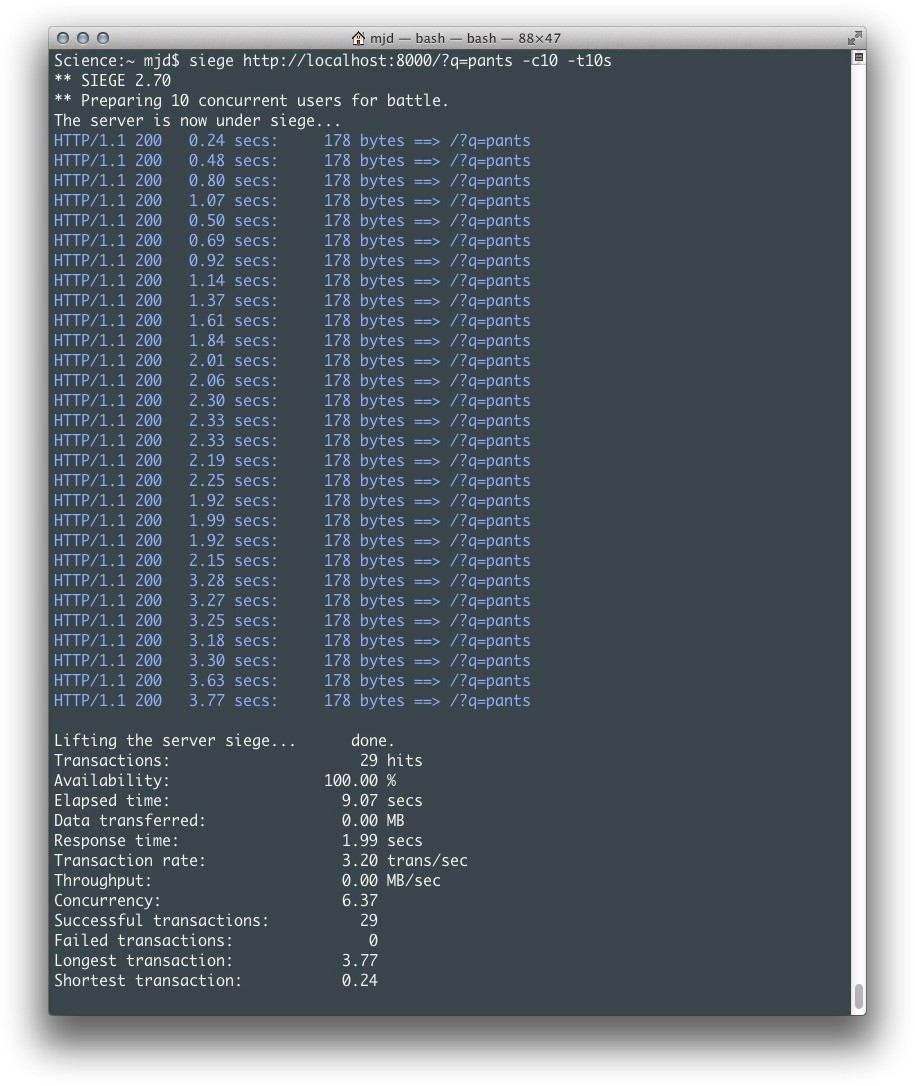
图5-2 同步推率获取
此时,不到10秒时间10个相似用户的平均响应时间达到了1.99秒,共计29次。请记住,这个例子只提供了一个非常简单的网页。如果你要添加其他Web服务或数据库的调用的话,结果会更糟糕。这种代码如果被 用到网站上,即便是中等强度的流量都会导致请求增长缓慢,甚至发生超时或失败。
5.1.3 基础异步调用¶
幸运的是,Tornado包含一个AsyncHTTPClient类,可以执行异步HTTP请求。它和代码清单5-1的同步客户端实现有一定的相似性,除了一些我们将要讨论的重要区别。代码清单5-2是其源代码。
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
import tornado.httpclient
import urllib
import json
import datetime
import time
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
class IndexHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
def get(self):
query = self.get_argument('q')
client = tornado.httpclient.AsyncHTTPClient()
client.fetch("http://search.twitter.com/search.json?" + \
urllib.urlencode({"q": query, "result_type": "recent", "rpp": 100}),
callback=self.on_response)
def on_response(self, response):
body = json.loads(response.body)
result_count = len(body['results'])
now = datetime.datetime.utcnow()
raw_oldest_tweet_at = body['results'][-1]['created_at']
oldest_tweet_at = datetime.datetime.strptime(raw_oldest_tweet_at,
"%a, %d %b %Y %H:%M:%S +0000")
seconds_diff = time.mktime(now.timetuple()) - \
time.mktime(oldest_tweet_at.timetuple())
tweets_per_second = float(result_count) / seconds_diff
self.write("""
<div style="text-align: center">
<div style="font-size: 72px">%s</div>
<div style="font-size: 144px">%.02f</div>
<div style="font-size: 24px">tweets per second</div>
</div>""" % (self.get_argument('q'), tweets_per_second))
self.finish()
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application(handlers=[(r"/", IndexHandler)])
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
AsyncHTTPClient的fetch方法并不返回调用的结果。取而代之的是它指定了一个callback参数;你指定的方法或函数将在HTTP请求完成时被调用,并使用HTTPResponse作为其参数。
client = tornado.httpclient.AsyncHTTPClient()
client.fetch("http://search.twitter.com/search.json?" + »
urllib.urlencode({"q": query, "result_type": "recent", "rpp": 100}),
callback=self.on_response)
在这个例子中,我们指定on_response方法作为回调函数。我们之前使用期望的输出转化Twitter搜索API请求到网页中的所有逻辑被搬到了on_response函数中。还需要注意的是@tornado.web.asynchronous装饰器的使用(在get方法的定义之前)以及在回调方法结尾处调用的self.finish()。我们稍后将简要的讨论他们的细节。
这个版本的应用拥有和之前同步版本相同的外观,但其性能更加优越。有多好呢?让我们看看基准测试的结果吧。
正如你在图5-3中所看到的,我们从同步版本的每秒3.20个事务提升到了12.59,在相同的时间内总共提供了118次请求。这真是一个非常大的改善!正如你所想象的,当扩展到更多用户和更长时间时,它将能够提供更多连接,并且不会遇到同步版本遭受的变慢的问题。
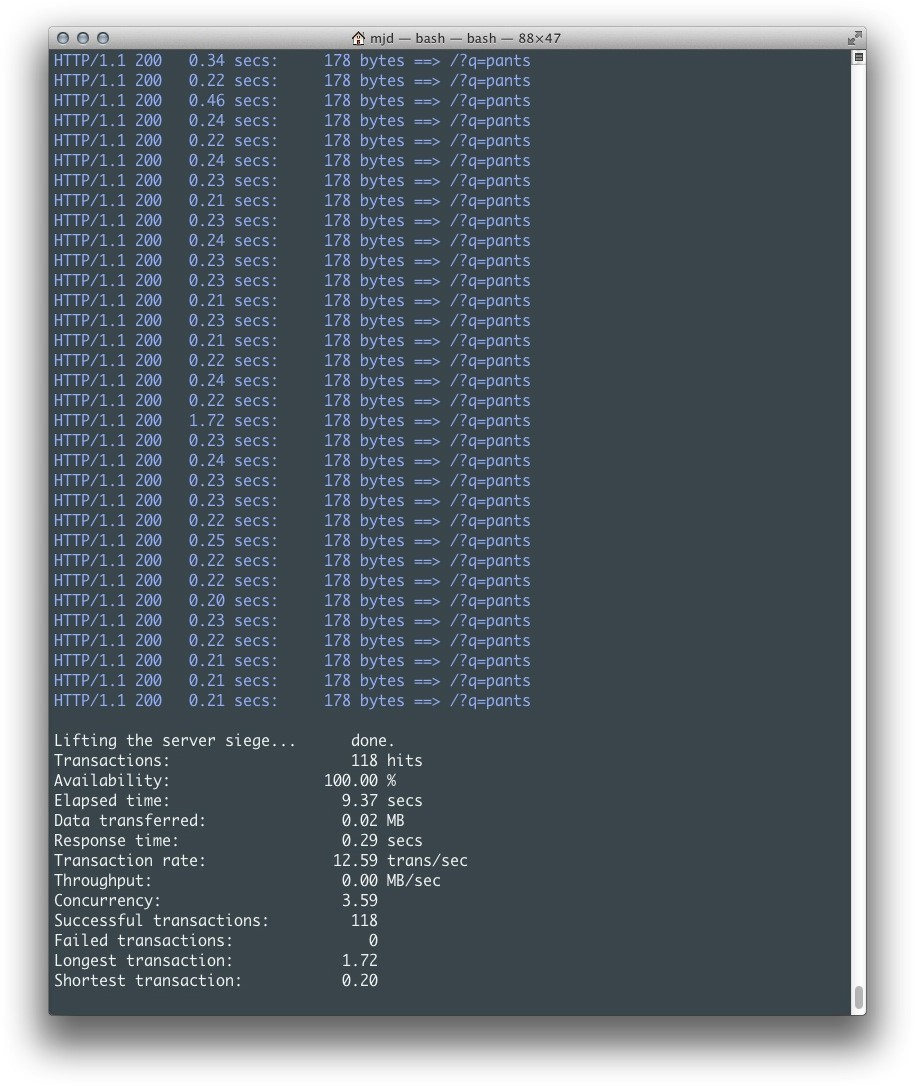
图5-3 异步推率获取
5.1.4 异步装饰器和finish方法¶
Tornado默认在函数处理返回时关闭客户端的连接。在通常情况下,这正是你想要的。但是当我们处理一个需要回调函数的异步请求时,我们需要连接保持开启状态直到回调函数执行完毕。你可以在你想改变其行为的方法上面使用@tornado.web.asynchronous装饰器来告诉Tornado保持连接开启,正如我们在异步版本的推率例子中IndexHandler的get方法中所做的。下面是相关的代码片段:
class IndexHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
def get(self):
query = self.get_argument('q')
[... other request handler code here...]
记住当你使用@tornado.web.asynchonous装饰器时,Tornado永远不会自己关闭连接。你必须在你的RequestHandler对象中调用finish方法来显式地告诉Tornado关闭连接。(否则,请求将可能挂起,浏览器可能不会显示我们已经发送给客户端的数据。)在前面的异步示例中,我们在on_response函数的write后面调用了finish方法:
[... other callback code ...]
self.write("""
<div style="text-align: center">
<div style="font-size: 72px">%s</div>
<div style="font-size: 144px">%.02f</div>
<div style="font-size: 24px">tweets per second</div>
</div>""" % (self.get_argument('q'), tweets_per_second))
self.finish()
5.1.5 异步生成器¶
现在,我们的推率程序的异步版本运转的不错并且性能也很好。不幸的是,它有点麻烦:为了处理请求 ,我们不得不把我们的代码分割成两个不同的方法。当我们有两个或更多的异步请求要执行的时候,编码和维护都显得非常困难,每个都依赖于前面的调用:不久你就会发现自己调用了一个回调函数的回调函数的回调函数。下面就是一个构想出来的(但不是不可能的)例子:
def get(self):
client = AsyncHTTPClient()
client.fetch("http://example.com", callback=on_response)
def on_response(self, response):
client = AsyncHTTPClient()
client.fetch("http://another.example.com/", callback=on_response2)
def on_response2(self, response):
client = AsyncHTTPClient()
client.fetch("http://still.another.example.com/", callback=on_response3)
def on_response3(self, response):
[etc., etc.]
幸运的是,Tornado 2.1版本引入了tornado.gen模块,可以提供一个更整洁的方式来执行异步请求。代码清单5-3就是使用了tornado.gen版本的推率应用源代码。让我们先来看一下,然后讨论它是如何工作的。
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
import tornado.httpclient
import tornado.gen
import urllib
import json
import datetime
import time
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
class IndexHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
@tornado.gen.engine
def get(self):
query = self.get_argument('q')
client = tornado.httpclient.AsyncHTTPClient()
response = yield tornado.gen.Task(client.fetch,
"http://search.twitter.com/search.json?" + \
urllib.urlencode({"q": query, "result_type": "recent", "rpp": 100}))
body = json.loads(response.body)
result_count = len(body['results'])
now = datetime.datetime.utcnow()
raw_oldest_tweet_at = body['results'][-1]['created_at']
oldest_tweet_at = datetime.datetime.strptime(raw_oldest_tweet_at,
"%a, %d %b %Y %H:%M:%S +0000")
seconds_diff = time.mktime(now.timetuple()) - \
time.mktime(oldest_tweet_at.timetuple())
tweets_per_second = float(result_count) / seconds_diff
self.write("""
<div style="text-align: center">
<div style="font-size: 72px">%s</div>
<div style="font-size: 144px">%.02f</div>
<div style="font-size: 24px">tweets per second</div>
</div>""" % (query, tweets_per_second))
self.finish()
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application(handlers=[(r"/", IndexHandler)])
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
正如你所看到的,这个代码和前面两个版本的代码非常相似。主要的不同点是我们如何调用Asynchronous对象的fetch方法。下面是相关的代码部分:
client = tornado.httpclient.AsyncHTTPClient()
response = yield tornado.gen.Task(client.fetch,
"http://search.twitter.com/search.json?" + \
urllib.urlencode({"q": query, "result_type": "recent", "rpp": 100}))
body = json.loads(response.body)
我们使用Python的yield关键字以及tornado.gen.Task对象的一个实例,将我们想要的调用和传给该调用函数的参数传递给那个函数。这里,yield的使用返回程序对Tornado的控制,允许在HTTP请求进行中执行其他任务。当HTTP请求完成时,RequestHandler方法在其停止的地方恢复。这种构建的美在于它在请求处理程序中返回HTTP响应,而不是回调函数中。因此,代码更易理解:所有请求相关的逻辑位于同一个位置。而HTTP请求依然是异步执行的,所以我们使用tornado.gen可以达到和使用回调函数的异步请求版本相同的性能,正如我们在图5-4中所看到的那样。
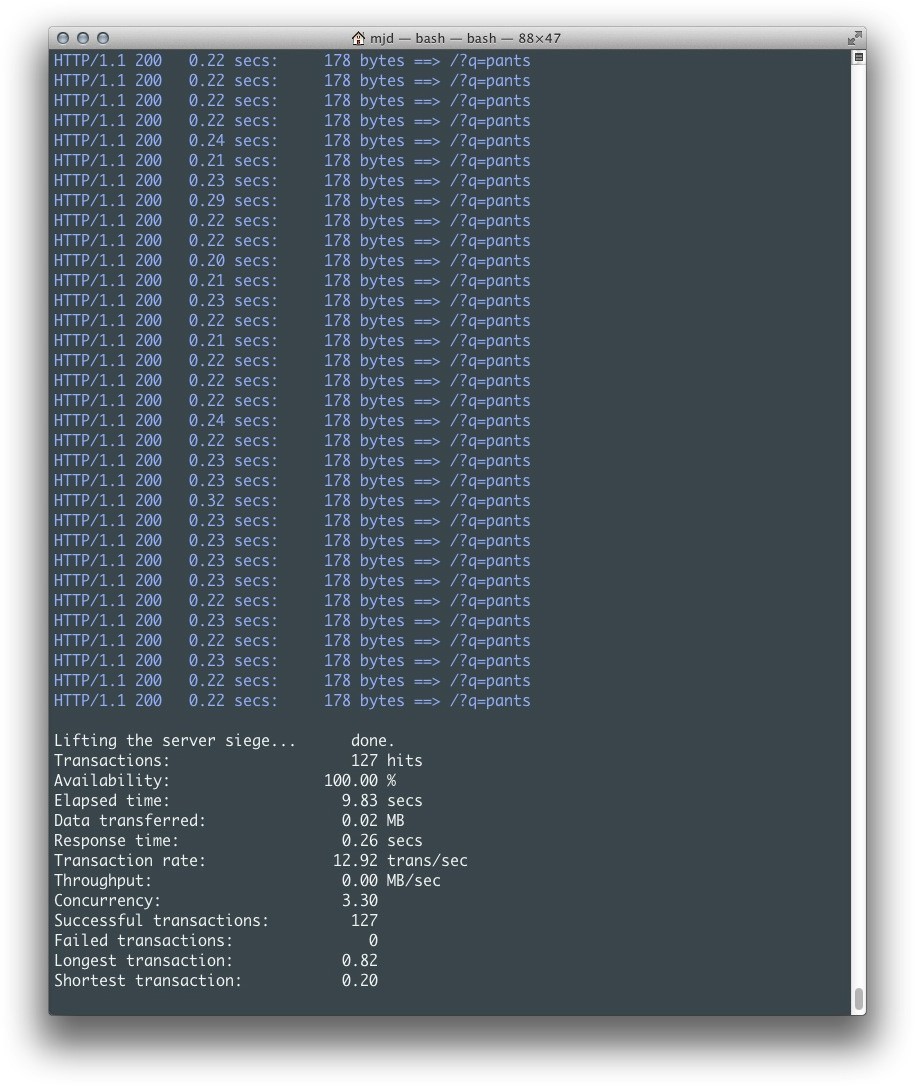
图5-4 使用tornado.gen的异步推率获取
记住@tornado.gen.engine装饰器的使用需要刚好在get方法的定义之前;这将提醒Tornado这个方法将使用tornado.gen.Task类。tornado.gen模块还哟一些其他类和函数可以方便Tornado的异步编程。查阅一下文档[1]是非常值得的。
使一切异步
在本章中我们使用了Tornado的异步HTTP客户端作为如何执行异步任务的实现。其他开发者也编写了针对其他任务的异步客户端库。志愿者们在Tornado wiki上维护了一个关于这些库的相当完整的列表。
一个重要的例子是bit.ly的asyncmongo,它可以异步的调用MongoDB服务器。这个库是我们的一个非常不错的选择,因为它是专门给Tornado开发者开发提供异步数据库访问的,不过对于使用其他数据库的用户而言,在这里也可以找到不错的异步数据存储库的选择。
5.1.6 异步操作总结¶
正如我们在前面的例子中所看到的,Tornado异步Web发服务不仅容易实现也在实践中有着不容小觑的能力。使用异步处理可以让我们的应用在长时间的API和数据库请求中免受阻塞之苦,最终更快地提供更多请求。尽管不是所有的处理都能从异步中受益--并且实际上尝试整个程序非阻塞会迅速使事情变得复杂--但Tornado的非阻塞功能可以非常方便的创建依赖于缓慢查询或外部服务的Web应用。
不过,值得注意的是,这些例子都非常的做作。如果你正在设计一个任何规模下带有该功能的应用,你可能希望客户端浏览器来执行Twitter搜索请求(使用JavaScript),而让Web服务器转向提供其他请求。在大多数情况下,你至少希望将结果缓存以便两次相同搜索项的请求不会导致再次向远程API执行完整请求。通常,如果你在后端执行HTTP请求提供网站内容,你可能希望重新思考如何建立你的应用。
考虑到这一点,在下一组示例中,我们将看看如何在前端使用像JavaScript这样的工具处理异步应用,让客户端承担更多工作,以提高你应用的扩展性。
5.2 使用Tornado进行长轮询¶
Tornado异步架构的另一个优势是它能够轻松处理HTTP长轮询。这是一个处理实时更新的方法,它既可以应用到简单的数字标记通知,也可以实现复杂的多用户聊天室。
部署提供实时更新的Web应用对于Web程序员而言是一项长期的挑战。更新用户状态、发送新消息提醒、或者任何一个需要在初始文档完成加载后由服务器向浏览器发送消息方法的全局活动。一个早期的方法是浏览器以一个固定的时间间隔向服务器轮询新请求。这项技术带来了新的挑战:轮询频率必须足够快以便通知是最新的,但又不能太频繁,当成百上千的客户端持续不断的打开新的连接会使HTTP请求面临严重的扩展性挑战。频繁的轮询使得Web服务器遭受"凌迟"之苦。
所谓的"服务器推送"技术允许Web应用实时发布更新,同时保持合理的资源使用以及确保可预知的扩展。对于一个可行的服务器推送技术而言,它必须在现有的浏览器上表现良好。最流行的技术是让浏览器发起连接来模拟服务器推送更新。这种方式的HTTP连接被称为长轮询或Comet请求。
长轮询意味着浏览器只需启动一个HTTP请求,其连接的服务器会有意保持开启。浏览器只需要等待更新可用时服务器"推送"响应。当服务器发送响应并关闭连接后,(或者浏览器端客户请求超时),客户端只需打开一个新的连接并等待下一个更新。
本节将包括一个简单的HTTP长轮询实时应用以及证明Tornado架构如何使这些应用更简单。
5.2.1 长轮询的好处¶
HTTP长轮询的主要吸引力在于其极大地减少了Web服务器的负载。相对于客户端制造大量的短而频繁的请求(以及每次处理HTTP头部产生的开销),服务器端只有当其接收一个初始请求和再次发送响应时处理连接。大部分时间没有新的数据,连接也不会消耗任何处理器资源。
浏览器兼容性是另一个巨大的好处。任何支持AJAX请求的浏览器都可以执行推送请求。不需要任何浏览器插件或其他附加组件。对比其他服务器端推送技术,HTTP长轮询最终成为了被广泛使用的少数几个可行方案之一。
我们已经接触过长轮询的一些使用。实际上,前面提到的状态更新、消息通知以及聊天消息都是目前流行的网站功能。像Google Docs这样的站点使用长轮询同步协作,两个人可以同时编辑文档并看到对方的改变。Twitter使用长轮询指示浏览器在新状态更新可用时展示通知。Facebook使用这项技术在其聊天功能中。长轮询如此流行的一个原因是它改善了应用的用户体验:访客不再需要不断地刷新页面来获取最新的内容。
5.2.2 示例:实时库存报告¶
这个例子演示了一个根据多个购物者浏览器更新的零售商库存实时计数服务。这个应用提供一个带有"Add to Cart"按钮的HTML书籍细节页面,以及书籍剩余库存的计数。一个购物者将书籍添加到购物车之后,其他访问这个站点的访客可以立刻看到库存的减少。
为了提供库存更新,我们需要编写一个在初始化处理方法调用后不会立即关闭HTTP连接的RequestHandler子类。我们使用Tornado内建的asynchronous装饰器完成这项工作,如代码清单5-4所示。
import tornado.web
import tornado.httpserver
import tornado.ioloop
import tornado.options
from uuid import uuid4
class ShoppingCart(object):
totalInventory = 10
callbacks = []
carts = {}
def register(self, callback):
self.callbacks.append(callback)
def moveItemToCart(self, session):
if session in self.carts:
return
self.carts[session] = True
self.notifyCallbacks()
def removeItemFromCart(self, session):
if session not in self.carts:
return
del(self.carts[session])
self.notifyCallbacks()
def notifyCallbacks(self):
for c in self.callbacks:
self.callbackHelper(c)
self.callbacks = []
def callbackHelper(self, callback):
callback(self.getInventoryCount())
def getInventoryCount(self):
return self.totalInventory - len(self.carts)
class DetailHandler(tornado.web.RequestHandler):
def get(self):
session = uuid4()
count = self.application.shoppingCart.getInventoryCount()
self.render("index.html", session=session, count=count)
class CartHandler(tornado.web.RequestHandler):
def post(self):
action = self.get_argument('action')
session = self.get_argument('session')
if not session:
self.set_status(400)
return
if action == 'add':
self.application.shoppingCart.moveItemToCart(session)
elif action == 'remove':
self.application.shoppingCart.removeItemFromCart(session)
else:
self.set_status(400)
class StatusHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
def get(self):
self.application.shoppingCart.register(self.async_callback(self.on_message))
def on_message(self, count):
self.write('{"inventoryCount":"%d"}' % count)
self.finish()
class Application(tornado.web.Application):
def __init__(self):
self.shoppingCart = ShoppingCart()
handlers = [
(r'/', DetailHandler),
(r'/cart', CartHandler),
(r'/cart/status', StatusHandler)
]
settings = {
'template_path': 'templates',
'static_path': 'static'
}
tornado.web.Application.__init__(self, handlers, **settings)
if __name__ == '__main__':
tornado.options.parse_command_line()
app = Application()
server = tornado.httpserver.HTTPServer(app)
server.listen(8000)
tornado.ioloop.IOLoop.instance().start()
让我们在看模板和脚本文件之前先详细看下shopping_cart.py。我们定义了一个ShoppingCart类来维护我们的库存中商品的数量,以及把商品加入购物车的购物者列表。然后,我们定义了DetailHandler用于渲染HTML;CartHandler用于提供操作购物车的接口;StatusHandler用于查询全局库存变化的通知。
DetailHandler为每个页面请求产生一个唯一标识符,在每次请求时提供库存数量,并向浏览器渲染index.html模板。CartHandler为浏览器提供了一个API来请求从访客的购物车中添加或删除物品。浏览器中运行的JavaScript提交POST请求来操作访客的购物车。我们将在下面的StatusHandler和ShoppingCart类的讲解中看到这些方法是如何作用域库存数量查询的。
class StatusHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
def get(self):
self.application.shoppingCart.register(self.async_callback(self.on_message))
关于StatusHandler首先需要注意的是get方法上面的@tornado.web.asynchronous装饰器。这使得Tornado在get方法返回时不会关闭连接。在这个方法中,我们只是注册了一个带有购物车控制器的回调函数。我们使用self.async_callback包住回调函数以确保回调函数中引发的异常不会使RequestHandler关闭连接。
在Tornado 1.1之前的版本中,回调函数必须被包在self.async_callback()方法中来捕获被包住的函数可能会产生的异常。不过,在Tornado 1.1或更新版本中,这不再是显式必须的了。
def on_message(self, count):
self.write('{"inventoryCount":"%d"}' % count)
self.finish()
每当访客操作购物车,ShoppingCart控制器为每个已注册的回调函数调用on_message方法。这个方法将当前库存数量写入客户端并关闭连接。(如果服务器不关闭连接的话,浏览器可能不会知道请求已经被完成,也不会通知脚本有过更新。)既然长轮询连接已经关闭,购物车控制器必须删除已注册的回调函数列表中的回调函数。在这个例子中,我们只需要将回调函数列表替换为一个新的空列表。在请求处理中被调用并完成后删除已注册的回调函数十分重要,因为随后在调用回调函数时将在之前已关闭的连接上调用finish(),这会产生一个错误。
最后,ShoppingCart控制器管理库存分批和状态回调。StatusHandler通过register方法注册回调函数,即添加这个方法到内部的callbacks数组。
def moveItemToCart(self, session):
if session in self.carts:
return
self.carts[session] = True
self.notifyCallbacks()
def removeItemFromCart(self, session):
if session not in self.carts:
return
del(self.carts[session])
self.notifyCallbacks()
此外,ShoppingCart控制器还实现了CartHandler中的addItemToCart和removeItemFromCart。当CartHandler调用这些方法,请求页面的唯一标识符(传给这些方法的session变量)被用于在调用notifyCallbacks之前标记库存。[2]
def notifyCallbacks(self):
for c in self.callbacks:
self.callbackHelper(c)
self.callbacks = []
def callbackHelper(self, callback):
callback(self.getInventoryCount())
已注册的回调函数被以当前可用库存数量调用,并且回调函数列表被清空以确保回调函数不会在一个已经关闭的连接上调用。
代码清单5-5是展示书籍列表变化的模板。
<html>
<head>
<title>Burt's Books – Book Detail</title>
<script src="//ajax.googleapis.com/ajax/libs/jquery/1.7.1/jquery.min.js"
type="text/javascript"></script>
<script src="{{ static_url('scripts/inventory.js') }}"
type="application/javascript"></script>
</head>
<body>
<div>
<h1>Burt's Books</h1>
<hr/>
<p><h2>The Definitive Guide to the Internet</h2>
<em>Anonymous</em></p>
</div>
<img src="static/images/internet.jpg" alt="The Definitive Guide to the Internet" />
<hr />
<input type="hidden" id="session" value="{{ session }}" />
<div id="add-to-cart">
<p><span style="color: red;">Only <span id="count">{{ count }}</span>
left in stock! Order now!</span></p>
<p>$20.00 <input type="submit" value="Add to Cart" id="add-button" /></p>
</div>
<div id="remove-from-cart" style="display: none;">
<p><span style="color: green;">One copy is in your cart.</span></p>
<p><input type="submit" value="Remove from Cart" id="remove-button" /></p>
</div>
</body>
</html>
当DetailHandler渲染index.html模板时,我们只是渲染了图书的详细信息并包含了必需的的JavaScript代码。此外,我们通过session变量动态地包含了一个唯一ID,并以count变量保存当前库存值。
最后,我们将讨论客户端的JavaScript代码。由于这是一本关于Tornado的书籍,因此我们直到现在一直使用的是Python,而这个例子中的客户端代码是至关重要的,我们至少要能够理解它的要点。在代码清单5-6中,我们使用了jQuery库来协助定义浏览器的页面行为。
$(document).ready(function() {
document.session = $('#session').val();
setTimeout(requestInventory, 100);
$('#add-button').click(function(event) {
jQuery.ajax({
url: '//localhost:8000/cart',
type: 'POST',
data: {
session: document.session,
action: 'add'
},
dataType: 'json',
beforeSend: function(xhr, settings) {
$(event.target).attr('disabled', 'disabled');
},
success: function(data, status, xhr) {
$('#add-to-cart').hide();
$('#remove-from-cart').show();
$(event.target).removeAttr('disabled');
}
});
});
$('#remove-button').click(function(event) {
jQuery.ajax({
url: '//localhost:8000/cart',
type: 'POST',
data: {
session: document.session,
action: 'remove'
},
dataType: 'json',
beforeSend: function(xhr, settings) {
$(event.target).attr('disabled', 'disabled');
},
success: function(data, status, xhr) {
$('#remove-from-cart').hide();
$('#add-to-cart').show();
$(event.target).removeAttr('disabled');
}
});
});
});
function requestInventory() {
jQuery.getJSON('//localhost:8000/cart/status', {session: document.session},
function(data, status, xhr) {
$('#count').html(data['inventoryCount']);
setTimeout(requestInventory, 0);
}
);
}
当文档完成加载时,我们为"Add to Cart"按钮添加了点击事件处理函数,并隐藏了"Remove form Cart"按钮。这些事件处理函数关联服务器的API调用,并交换添加到购物车接口和从购物车移除接口。
function requestInventory() {
jQuery.getJSON('//localhost:8000/cart/status', {session: document.session},
function(data, status, xhr) {
$('#count').html(data['inventoryCount']);
setTimeout(requestInventory, 0);
}
);
}
requestInventory函数在页面完成加载后经过一个短暂的延迟再进行调用。在函数主体中,我们通过到/cart/status的HTTP GET请求初始化一个长轮询。延迟允许在浏览器完成渲染页面时使加载进度指示器完成,并防止Esc键或停止按钮中断长轮询请求。当请求成功返回时,count的内容更新为当前的库存量。图5-5所示为展示全部库存的两个浏览器窗口。
图5-5 长轮询示例:全部库存
现在,当你运行服务器,你将可以加载根URL并看到书籍的当前库存数量。打开多个细节页的浏览器窗口,并在其中一个窗口点击"Add to Cart"按钮。其余窗口的剩余库存数量会立刻更新,如果5-6所示。
图5-6 长轮询示例:一个物品在购物车中
这是一个非常简单的购物车实现,可以肯定的是--没有逻辑确保我们不会跌破总库存量,更不用说数据无法在Tornado应用的不同调用间或同一服务器并行的应用实例间保留。我们将这些改善作为练习留给读者。
5.2.3 长轮询的缺陷¶
正如我们所看到的,HTTP长轮询在站点或特定用户状态的高度交互反馈通信中非常有用。但我们也应该知道它的一些缺陷。
当使用长轮询开发应用时,记住对于浏览器请求超时间隔无法控制是非常重要的。由浏览器决定在任何中断情况下重新开启HTTP连接。另一个潜在的问题是许多浏览器限制了对于打开的特定主机的并发请求数量。当有一个连接保持空闲时,剩下的用来下载网站内容的请求数量就会有限制。
此外,你还应该明白请求是怎样影响服务器性能的。再次考虑购物车应用。由于在库存变化时所有的推送请求同时应答和关闭,使得在浏览器重新建立连接时服务器受到了新请求的猛烈冲击。对于像用户间聊天或消息通知这样的应用而言,只有少数用户的连接会同时关闭,这就不再是一个问题了。
5.3 Tornado与WebSockets¶
WebSockets是HTML5规范中新提出的客户-服务器通讯协议。这个协议目前仍是草案,只有最新的一些浏览器可以支持它。但是,它的好处是显而易见的,随着支持它的浏览器越来越多,我们将看到它越来越流行。(和以往的Web开发一样,必须谨慎地坚持依赖可用的新功能并能在必要时回滚到旧技术的务实策略。)
WebSocket协议提供了在客户端和服务器间持久连接的双向通信。协议本身使用新的ws://URL格式,但它是在标准HTTP上实现的。通过使用HTTP和HTTPS端口,它避免了从Web代理后的网络连接站点时引入的各种问题。HTML5规范不只描述了协议本身,还描述了使用WebSockets编写客户端代码所需要的浏览器API。
由于WebSocket已经在一些最新的浏览器中被支持,并且Tornado为之提供了一些有用的模块,因此来看看如何使用WebSockets实现应用是非常值得的。
5.3.1 Tornado的WebSocket模块¶
Tornado在websocket模块中提供了一个WebSocketHandler类。这个类提供了和已连接的客户端通信的WebSocket事件和方法的钩子。当一个新的WebSocket连接打开时,open方法被调用,而on_message和on_close方法分别在连接接收到新的消息和客户端关闭时被调用。
此外,WebSocketHandler类还提供了write_message方法用于向客户端发送消息,close方法用于关闭连接。
class EchoHandler(tornado.websocket.WebSocketHandler):
def open(self):
self.write_message('connected!')
def on_message(self, message):
self.write_message(message)
正如你在我们的EchoHandler实现中所看到的,open方法只是使用WebSocketHandler基类提供的write_message方法向客户端发送字符串"connected!"。每次处理程序从客户端接收到一个新的消息时调用on_message方法,我们的实现中将客户端提供的消息原样返回给客户端。这就是全部!让我们通过一个完整的例子看看实现这个协议是如何简单的吧。
5.3.2 示例:使用WebSockets的实时库存¶
在本节中,我们可以看到把之前使用HTTP长轮询的例子更新为使用WebSockets是如何简单。但是,请记住,WebSockets还是一个新标准,只有最新的浏览器版本可以支持它。Tornado支持的特定版本的WebSocket协议版本只在Firefox 6.0或以上、Safari 5.0.1或以上、Chrome 6或以上、IE 10预览版或以上版本的浏览器中可用。
不去管免责声明,让我们先看看源码吧。除了服务器应用需要在ShoppingCart和StatusHandler类中做一些修改外,大部分代码保持和之前一样。代码清单5-7看起来会很熟悉。
import tornado.web
import tornado.websocket
import tornado.httpserver
import tornado.ioloop
import tornado.options
from uuid import uuid4
class ShoppingCart(object):
totalInventory = 10
callbacks = []
carts = {}
def register(self, callback):
self.callbacks.append(callback)
def unregister(self, callback):
self.callbacks.remove(callback)
def moveItemToCart(self, session):
if session in self.carts:
return
self.carts[session] = True
self.notifyCallbacks()
def removeItemFromCart(self, session):
if session not in self.carts:
return
del(self.carts[session])
self.notifyCallbacks()
def notifyCallbacks(self):
for callback in self.callbacks:
callback(self.getInventoryCount())
def getInventoryCount(self):
return self.totalInventory - len(self.carts)
class DetailHandler(tornado.web.RequestHandler):
def get(self):
session = uuid4()
count = self.application.shoppingCart.getInventoryCount()
self.render("index.html", session=session, count=count)
class CartHandler(tornado.web.RequestHandler):
def post(self):
action = self.get_argument('action')
session = self.get_argument('session')
if not session:
self.set_status(400)
return
if action == 'add':
self.application.shoppingCart.moveItemToCart(session)
elif action == 'remove':
self.application.shoppingCart.removeItemFromCart(session)
else:
self.set_status(400)
class StatusHandler(tornado.websocket.WebSocketHandler):
def open(self):
self.application.shoppingCart.register(self.callback)
def on_close(self):
self.application.shoppingCart.unregister(self.callback)
def on_message(self, message):
pass
def callback(self, count):
self.write_message('{"inventoryCount":"%d"}' % count)
class Application(tornado.web.Application):
def __init__(self):
self.shoppingCart = ShoppingCart()
handlers = [
(r'/', DetailHandler),
(r'/cart', CartHandler),
(r'/cart/status', StatusHandler)
]
settings = {
'template_path': 'templates',
'static_path': 'static'
}
tornado.web.Application.__init__(self, handlers, **settings)
if __name__ == '__main__':
tornado.options.parse_command_line()
app = Application()
server = tornado.httpserver.HTTPServer(app)
server.listen(8000)
tornado.ioloop.IOLoop.instance().start()
除了额外的导入语句外,我们只需要改变ShoppingCart和StatusHandler类。首先需要注意的是,为了获得WebSocketHandler的功能,需要使用tornado.websocket模块。
在ShoppingCart类中,我们只需要在通知回调函数的方式上做一个轻微的改变。因为WebSOckets在一个消息发送后保持打开状态,我们不需要在它们被通知后移除内部的回调函数列表。我们只需要迭代列表并调用带有当前库存量的回调函数:
def notifyCallbacks(self):
for callback in self.callbacks:
callback(self.getInventoryCount())
另一个改变是添加了unregisted方法。StatusHandler会在WebSocket连接关闭时调用该方法移除一个回调函数。
def unregister(self, callback):
self.callbacks.remove(callback)
大部分改变是在继承自tornado.websocket.WebSocketHandler的StatusHandler类中的。WebSocket处理函数实现了open和on_message方法,分别在连接打开和接收到消息时被调用,而不是为每个HTTP方法实现处理函数。此外,on_close方法在连接被远程主机关闭时被调用。
class StatusHandler(tornado.websocket.WebSocketHandler):
def open(self):
self.application.shoppingCart.register(self.callback)
def on_close(self):
self.application.shoppingCart.unregister(self.callback)
def on_message(self, message):
pass
def callback(self, count):
self.write_message('{"inventoryCount":"%d"}' % count)
在实现中,我们在一个新连接打开时使用ShoppingCart类注册了callback方法,并在连接关闭时注销了这个回调函数。因为我们依然使用了CartHandler类的HTTP API调用,因此不需要监听WebSocket连接中的新消息,所以on_message实现是空的。(我们覆写了on_message的默认实现以防止在我们接收消息时Tornado抛出NotImplementedError异常。)最后,callback方法在库存改变时向WebSocket连接写消息内容。
这个版本的JavaScript代码和之前的非常相似。我们只需要改变其中的requestInventory函数。我们使用HTML5 WebSocket API取代长轮询资源的AJAX请求。参见代码清单5-8.
function requestInventory() {
var host = 'ws://localhost:8000/cart/status';
var websocket = new WebSocket(host);
websocket.onopen = function (evt) { };
websocket.onmessage = function(evt) {
$('#count').html($.parseJSON(evt.data)['inventoryCount']);
};
websocket.onerror = function (evt) { };
}
在创建了一个到ws://localhost:8000/cart/status的心得WebSocket连接后,我们为每个希望响应的事件添加了处理函数。在这个例子中我们唯一关心的事件是onmessage,和之前版本的requestInventory函数一样更新count的内容。(轻微的不同是我们必须手工解析服务器送来的JSON对象。)
就像前面的例子一样,在购物者添加书籍到购物车时库存量会实时更新。不同之处在于一个持久的WebSocket连接取代了每次长轮询更新中重新打开的HTTP请求。
5.3.3 WebSockets的未来¶
WebSocket协议目前仍是草案,在它完成时可能还会修改。然而,因为这个规范已经被提交到IETF进行最终审查,相对而言不太可能会再面临重大的改变。正如本节开头所提到的那样,WebSocket的主要缺陷是目前只支持最新的一些浏览器。
尽管有上述警告,WebSockets仍然是在浏览器和服务器之间实现双向通信的一个有前途的新方法。当协议得到了广泛的支持后,我们将开始看到更加著名的应用的实现。
[2] 下面的这组代码书中使用的不是前面的代码,这里为了保持一致修改为和前面的代码一样。